





























技术园地
TECHNOLOGY

【技术分享】轻量级语言模型在邮件业务中的应用:从防垃圾训练到高效部署
发布时间:2025-12-19 / 浏览次数:955次

给IT小伙伴们介绍一些100M~3亿参数规模的主流轻量模型,探讨其在邮件相关业务中的适用性,并提供选型建议与部署实践指南。
以下是一些适用于邮件系统的轻量级模型及其关键特性:
| 模型名称 | 参数量 | 特点 | 适用场景 |
| DistilBERT | ~66M | BERT 的蒸馏版本,速度快40%,保留95%性能 | 文本分类、命名实体识别 |
| TinyBERT | ~14M~67M | 华为推出的超轻量 BERT,支持分层蒸馏 | 移动端 NLP 任务 |
| MobileBERT | ~25M | 专为移动端优化,推理延迟<100ms(Pixel 4) | 手机端实时应用 |
| ALBERT-Base | ~12M | 参数共享压缩,Base 版效果接近 BERT-Base | 低资源文本理解 |
| MiniLM v2 | ~33M | 微软蒸馏模型,量化后仅 1.7MB | 边缘设备嵌入 |
性能参考:
在 GLUE 基准测试中,66M 的 DistilBERT 达到 82.8 分(BERT-Base 84.8 分),推理速度快 60%。
1. 防垃圾邮件训练(Spam Detection)
使用轻量模型对邮件标题与正文进行分类,判断是否为垃圾邮件。例如:
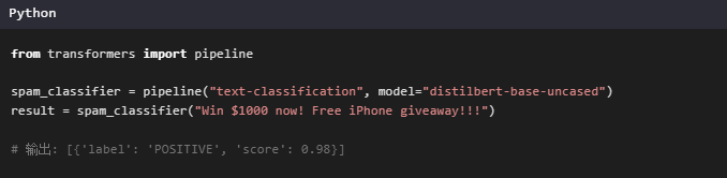
推荐模型:
DistilBERT:适合英文邮件分类
Chinese-BERT-wwm:中文邮件场景首选
优势:
快速响应(CPU 上约 50ms/句)
显存需求低(FP16 量化后可降至 500MB)
2. 邮件自动归类(Email Categorization)
对邮件内容进行自动分类,如“工作”、“个人”、“促销”、“通知”等类别标签。
推荐模型:
RoBERTa-Tiny(300M):比 BERT-Base 小 4 倍但性能相当
ELECTRA-Small(410M):数据效率高,适合训练样本较少的场景
示例代码:

3. 邮件摘要生成(Summarization)
虽然轻量模型不适合长文本生成,但在邮件摘要任务中仍可使用蒸馏版模型实现基础功能。
推荐模型:
MiniLM-L12-H384-uncased:轻量级摘要生成模型,适合短邮件内容
(1) 本地部署(普通电脑即可)
显存需求:<2GB(FP16 量化后可降至 500MB)
推理速度:CPU 上约 50ms/句(i7-11800H)
(2) 移动端部署(App 内集成)
工具推荐:ONNX Runtime + Quantization
压缩效果:TinyBERT 量化后仅 4.3MB(iOS/Android 通用)
适用于移动端邮件客户端的实时内容分析与提示功能。
(3) 云服务部署成本参考(AWS)
| 模型规模 | AWS inf1 实例推理成本(每千次请求) |
| 100M | $0.0001 |
| 300M | $0.0003 |
适合中小型企业或 SaaS 平台快速上线邮件 AI 功能。
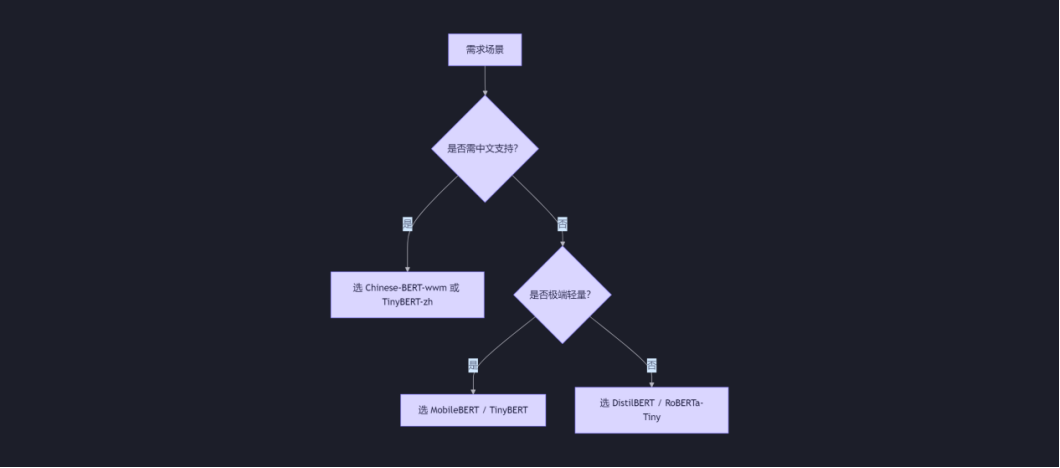
如果你正在考虑在邮件系统中引入轻量级语言模型,请根据以下问题评估:
硬件环境:是否有 GPU?内存多少?
任务类型:文本分类 / 问答 / 生成?
语言需求:英文 / 中文 / 多语言?
进阶方向:
-
微调教程:可在 Hugging Face 上找到预训练模型并进行 fine-tuning
- 量化压缩:使用 ONNX + quantize 技术进一步减小模型体积
- 边缘部署:结合 TensorFlow Lite 或 Core ML 实现移动设备上的高性能推理
